How richer semantics in XBRL could make financial data far more useful
for AI agents and modern data platforms
Introduction: The Growing Importance of Semantic Relationships
One of the most interesting developments in both artificial intelligence and data management is the growing recognition that relationships matter as much as data itself.
Neuroscientists and cognitive psychologists have long argued that humans build internal world models through semantic relationships.
Modern AI systems are attempting something similar. Deep Neural Networks and Large Language Models (LLMs) rely on probabilistic and stochastic techniques to construct statistical models of relationships between concepts and use those relationships to generate responses and make predictions.
Interestingly, the XBRL community has been dealing with similar challenges for over two decades. XBRL is primarily used for regulatory reporting frameworks, however, it has always been more than a reporting format. At its best, it is a structured way of expressing meaning, relationships, and validation rules so that data can be checked against a standardised model.
XBRL continues to evolve as a global standard. The Open Information Model (OIM) initiative will provide an updated set of specifications that will modernise and make XBRL simpler to use.
As part of this work, Financial Accounting Standards Board (FASB) and XBRL US are looking to enrich this XBRL update with a new set of Meta Model Relationships.
While these additions may appear technical, they represent something more significant. These new relationship types could improve the quality of XBRL models and the reliability of the reported data. In doing so they would also make XBRL data more AI ready.
This article discusses if XBRL can play a part in a broader movement across data management, business intelligence, and AI toward richer semantic models, ontologies, and machine-understandable meaning.
XBRL and the Need for Better Models
XBRL is now more than twenty-five years old. Over time, it has evolved through a patchwork of specifications layered on top of the original XBRL 2.1 standard. While this approach enabled innovation, many members of the XBRL community now view the architecture as increasingly difficult to maintain and extend.
At its core, XBRL enables a model (Taxonomy) to be developed that details the concepts to be used in a report, the hierarchical relationships between these concepts, the dimensional relationships, plus a myriad of other related information, e.g., table rendering structures, calculation relationships, etc.
These relationships form the foundation of XBRL’s validation capabilities and hence its widespread use for regulatory reporting.
Validation occurs at multiple levels, based upon these relationships:
- First, submitted XBRL report data (instance document) is confirmed to be for a valid concept in the model (Taxonomy), and that the information is of the correct data type.
- Calculation definitions allow simple addition and subtraction relationships to be described so that reported values can be checked to aggregate correctly within an order of tolerance.
- Third, XBRL Formula provides more sophisticated validation through complex business rules and assertions.
If a relationship is not defined in the Taxonomy, the model cannot easily use it for validation, inference, or better tagging guidance. In other words, the quality of the reporting framework depends heavily on the quality of the underlying relationship model.
Unfortunately, building and maintaining high-quality Taxonomies remains difficult. Part of the problem lies in XBRL’s historical foundations.
The standard was developed during an era when XML was widely viewed as the future of structured and semi-structured data. While XML provided flexibility and interoperability, it also introduced complexity that remains a barrier today.
Modern data tools and languages tend to be more flexible, more accessible, and more compatible with broader data engineering workflows than XML-based systems.
This matters because the modelling experience is not just a convenience issue. It shapes who can participate in building and maintaining taxonomies, and how quickly those taxonomies can evolve.
For example, XBRL Formula relies heavily on XPath, an XML-centric programming language. As a result, business rules often require developers with both technical expertise and domain knowledge. This makes Taxonomy maintenance challenging for business users and subject matter experts.
These challenges are one reason why many organizations continue to rely on spreadsheets and PDF-based reporting processes despite their well-known limitations.
The XBRL community started the Open Information Model (OIM) initiative to address many of these limitations. OIM seeks to free XBRL from its XML constraints by supporting alternative formats and simplifying the overall architecture. The initiative also aims to correct shortcomings in the original specifications while consolidating and modernizing the various extensions that have accumulated over time.
Significant progress has already been made. XBRL data can now be represented using formats such as:
- CSV for highly compressed, large-scale datasets
- JSON for web applications and modern integration scenarios
The next major milestone is enabling XBRL Taxonomies to be defined and maintained using more accessible formats, such as JSON.
As this work has progressed, FASB and XBRL US have identified that the existing XBRL specifications lack several relationship types that are essential for fully representing business meaning or for checking the quality of the model embedded in the Taxonomy.
The Missing Meta Model Relationships
Missing relationship types matter because, per above, XBRL depends on relationships to validate reports. When the relationships are incomplete or underspecified, errors can slip through, or the Taxonomy can become harder to test for correctness and completeness. This is especially significant where reporting precision is essential, such as in regulatory filings or consolidated financial statements.
The proposed relationships are not simply academic enhancements; they are expected to deliver practical benefits across any reporting ecosystem:
- For preparers, they improve the process of selecting appropriate tags.
- For XBRL data consumers, the relationships provide additional context that improves analysis and interpretation.
- For Taxonomy designers and regulators, the relationships create new opportunities for validation and business rule creation.
These benefits are not limited to improving individual XBRL filings but reflect a deeper shift: making relationships that were previously implicit in corporate reporting and accounting practice explicit and machine-readable.
FASB and XBRL US have identified some general reporting relationships between elements that it believes are missing from XBRL, such as:
- Aggregate-other, which explicitly identifies the “other” component of an aggregation. For example, current assets will typically include cash, receivables, inventory, a few other items, and a component for immaterial items — ‘Other’. This latter concept would be clearly identified by the new type, preventing other ‘Others’ if you will.
- Concept-dimensional-equivalent. It identifies places in the Taxonomy where the same accounting concept is conveyed with a single element but also someplace else in the Taxonomy, where the concept is defined by using a different primary element and a dimension-member combination.
- Traits: These group concepts across the Taxonomy model, so “Unsecured Debt” has a trait of “unsecured” as does “Commercial Paper”. This can be extremely useful in XBRL Taxonomy testing and validation as it allows users to search for elements based upon accounting traits and can ensure that conflicting accounting attributes are not assigned to an element. This is important because one of the biggest bottlenecks in XBRL reporting frameworks is not the absence of data, but the cost of repeatedly verifying that the Taxonomy model works and issuers can use it.
Beyond these general reporting relationship types, they identified a set of accounting-specific relationships that are especially important for financial reporting. These are the relationships accountants already understand instinctively, because they are taught these as part of the logic of financial reporting and consolidation. These relationships are also not explicitly expressed in the financial statements and are not visible as explicit constructs in XBRL taxonomies as there is no relationship type to describe them.
The easiest way to understand the proposed relationships is through examples.
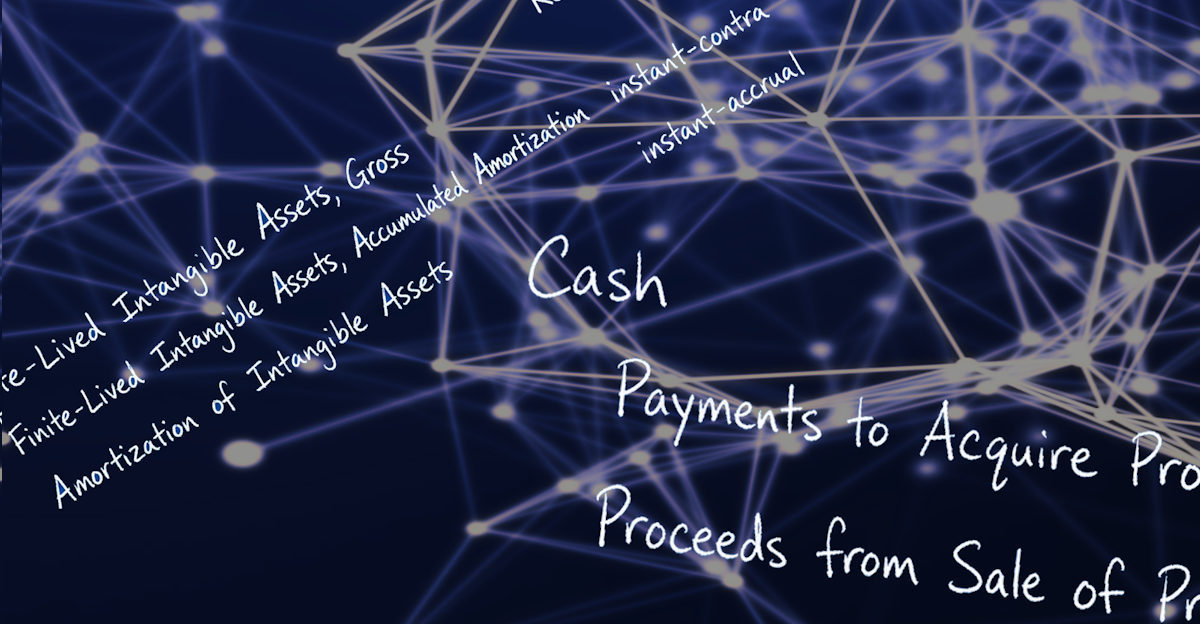
Instant-accrual and Instant-contra
- XBRL understands a ‘Credit’ in contrast to a ‘Debit’ but +/- signs in an aggregation are a continual reporting issue. This type explicitly states that an element adds to an aggregate (accrual) or subtracts (contra).

- In this example, “Amortization of Intangible Assets” accrues into “Finite-Lived Intangible Assets, Accumulated Amortization,” which is the contra account to “Finite-Lived Intangible Assets, Gross.”
- The relationship is more clearly defined and helps verify that the use of such elements is correct.
Instant-inflow and Instant-outflow
- Indicates a relationship between a balance (instant element) and a flow during a period (duration element) with one type for inflows and one for outflow elements.

- In this example, “Proceeds from Sale of Property, Plant, and Equipment” is the inflow item and “Payments to Acquire Property, Plant, and Equipment” is the outflow item to “Cash”.
- Again, a much clearer description of the relationship in accounting terms helps to verify that the correct tags are used in a balance calculation and from a model validation standpoint, anything that is an inflow or outflow, should not be used in say an income statement.
These examples may seem modest at first glance, but they are highly significant in a reporting Taxonomy, for example, if a concept is clearly marked as a cash inflow, it gives the preparer a better cue than a generic label alone, it can also be tested as part of an extension Taxonomy validation (issuer specific). That reduces ambiguity and improves consistency across filings.
Taken together, these changes could uncover a meaningful number of issues in existing taxonomies. That is not a flaw in the proposal; it is part of its value. Better semantics do not just make the model prettier. They expose weaknesses, inconsistencies, and ambiguous modelling choices that would otherwise remain hidden until users encounter them in production.
A full set of materials on the Meta Model Relationships, including the XBRL Taxonomy can be found on the FASB website: GAAP Meta Model Relationships Taxonomy.
Defining new relationship types does not need to stop with accounting, other types specific to other domain areas, such as ESG, Health, could also be developed and used to extend the XBRL specifications.
Setting aside for now the questions of how these domain relationships are packaged and how far the XBRL Standards Group take this next update in XBRL specifications, I believe that the addition of new relationship types to XBRL is a very important move to enrich the XBRL model, and, hence, making XBRL data not only more useful for validation, but also more compatible with systems that depend on explicit semantic structure, including modern AI applications.
That broader vision is important because it aligns with where data architecture is heading. The industry is increasingly focused on meaning, not just storage. Data platforms are racing to offer semantic layers, knowledge graphs, and governance-aware modelling tools because raw schemas alone are not enough for modern AI and analytics use cases.
The Semantic Layer Revolution and AI Agents
A semantic layer sits between raw data and applications. It defines business meaning, relationships, calculations, and context so that both humans and AI systems interpret data consistently. In early 2026, every major data platform made an announcement in this area:
- Snowflake released Semantic View Autopilot
- Databricks released their Unity Catalog Business Semantics
- Microsoft unveiled Fabric IQ Ontology
- At Google Cloud Next ’26, Google announced Knowledge Catalog and Enterprise Knowledge Graph
These announcements reflect a broad industry recognition that AI agents need more than raw tables and schemas to work upon and that meaning must be made explicit if they want reliable outputs.
Retrieval-Augmented Generation (RAG) has been a common approach to extend the AI Model with local ‘domain’ metadata, i.e. for enterprise knowledge to be reflected in an AI system. These extended AI models make AI applications less brittle in production systems by giving them better context and structure.
However, it also reveals a broader truth that without an underlying semantic model, AI systems struggle to stay grounded in domain reality.
The move to agentic AI explodes this need for domain knowledge.
- The standard AI Chatbot is ‘passive’ — you ask a question, it gives an answer.
- Agentic AI, however, is ‘active’ — you give it a goal and the autonomous AI software plans steps, calls APIs, uses tools, and makes decisions.
Building semantic models remains difficult — creating ontologies, defining relationships, validating semantics, and maintaining consistency has traditionally been a highly specialised skillset.
This could become one of the biggest bottlenecks in AI adoption. Fortunately, new tools are beginning to emerge.
Vendors such as Timbr, Astrobee, and others are exploring AI-assisted generation of semantic models from technical metadata and existing data structures.
The automation of gathering ‘knowledge’ to define the model, creating the set of relationships — the semantic model — and then testing the outputs from the model will be critical for the age of AI agents that operate autonomously.
The Convergence of Semantic Layers and XBRL
This is where XBRL becomes especially interesting. The logic of semantic modelling in XBRL resembles the logic now being applied in enterprise data platforms.
- Both seek to define meaning.
- Both focus on relationships.
- Both aim to help systems understand rather than merely process rows and columns.
It therefore appears obvious to me that they should converge.
However, whereas XBRL is primarily a standard driven by domain experts and practitioners who have worked with technical people to define a standard, albeit today with many imperfections, semantic layers are designed by technical people and typically need to get domain people involved to define relationships such as those defined by the FASB.
From an XBRL perspective, engaging with large data platforms would lift XBRL out of its very niche space and broaden its appeal.
For the data platform vendors looking for mature semantic structures, then they should look no further than XBRL, for general business reporting data.
The opportunities are compelling.
The real opportunity lies in tooling. If modern tools can generate semantic layers from database schemas, then in principle similar tools could generate a basic XBRL Taxonomy, then allow domain experts to refine the relationships through simple interfaces.
Likewise, a semantic layer could potentially be generated from an XBRL Taxonomy, including the richer relationships proposed by OIM and FASB. That would reduce manual effort and widen participation.
If such tooling matures, the impact on adoption would be immense. XBRL Taxonomy creation is currently a heavily manual process that requires both domain expertise and technical skill.
A poorly designed Taxonomy produces a poor reporting framework, so tools that use the relationships that help domain experts to verify and test a model would be extremely important in improving XBRL usage.
Such tooling could also be repurposed to help Issuers to find a better set of concepts to tag their reports and a better method for anchoring new specific concepts. Improving the quality for the data they submit in regulatory reports.
There is a feedback loop here. Better data attracts more use, and more use creates stronger incentives to improve data quality further. That is exactly the kind of self-reinforcing cycle that can transform a reporting standard from a compliance burden into a strategic asset. I highlighted this in a recent article regarding Digital First reporting.
Conclusion: Where this Leads
Firstly, the introduction of new Meta Model Relationships should be understood as part of a broader evolution of the XBRL Model, not as a niche enhancement. Without these types of relationships, XBRL models cannot fully express the semantic structure that modern data platforms and AI systems will rely on.
In that sense, the new Meta Model Relationships are a prerequisite for broader interoperability and reflect a broader shift toward semantic understanding that is occurring across modern data architectures.
The key realisation is that the exact limitation that makes XBRL harder to use today is the same limitation that prevents data from being used by AI systems.
The proposed relationships from XBRL US and FASB enrich XBRL’s ability to represent business meaning. They make implicit accounting knowledge explicit and create new opportunities for validating XBRL models, automation, and XBRL data analysis.
As the discussions on the benefits of semantic layers intensify and data platform providers provide a deeper set of tools, XBRL needs to evolve into a format that can be consumed and integrated simply with modern data platforms and hence fit naturally into emerging semantic ecosystems.
Richer semantic relationships inevitably increase modelling complexity and will require careful governance to ensure consistency across Taxonomies. However, XBRL already possesses a significant advantage: decades of domain expertise embedded within existing proven reporting frameworks and Taxonomies.
This vision will not be achieved overnight. Standards evolve slowly, especially when they sit at the intersection of regulatory reporting and accounting practice. However, there is a clear direction forward for the XBRL community.
The real significance of Meta Model Relationships is not that they improve XBRL validation. It is that they move XBRL closer to becoming a business-orientated, machine-understandable semantic layer. In a world increasingly shaped by AI agents, that may prove to be far more important than just regulatory reporting itself.
The author is Martin DeVille of AM2 Limited
This article was originally published on Medium.com as part of the Digital Reporting Made Simple publication.